Nataliia Stulova Senior Research Scientist 
Yevhenii Peteliev Senior Research Engineer
LLLMs: Local Large Language Models

- #Artificial Intelligence
• 34 min read
Introduction
This article discusses the evolution of Local Large Language Models (LLMs) and their potential applications. In recent years, neural network development has progressed significantly, enabling these models to be used for a variety of tasks. Foundation models, as referred to by the Center for Research on Foundation Models, are trained on broad data and can be fine-tuned for various tasks. The article reviews the LLaMA family of LLMs developed by Meta AI, the RedPajama and Alpaca variants, MPT family by MosaicML, and GPT-J by EleutherAI. It further elucidates concepts such as quantization which allows running these models on consumer-grade devices, discusses potential issues in running these models, and compares solutions like renting cloud power or building one's own server to calculate the cost of using a prompt. The article concludes with potential integration possibilities of these models.
Background
Developing neural networks (NNs) is an ongoing process, and in the last 70+ years, we have seen a lot of progress.
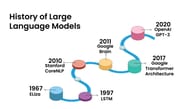
The first and simplest NNs of the 1950s — the perceptrons — could only do some simple binary classification. As more complex architectures of neural networks were proposed, the technology applications have expanded to natural text processing and image recognition, like handwritten postal ZIP code numbers recognition (1989).
Around mid 2000s the long short-term memory networks could already tackle speech and handwriting recognition and text-to-speech synthesis. Another breakthrough came about 10 years later with autoencoders and generative adversarial networks, now able not only to classify input text or images but produce them too.
However, until 2017 and the transformer architecture that allowed the use of orders of magnitude larger datasets for NN training, the dominating approach was basically "one network, one application." Large language models based on the transformer architecture changed that, and now, instead of building a specialized tool (that can only do 1 task), we take a generic tool and adapt it to the current task (but the same tool can do more tasks).
Foundation models
In August 2021, the Center for Research on Foundation Models (CRFM) at the Stanford Institute for Human-Centered Artificial Intelligence (HAI) introduced the term "foundation model." This term refers to any model that undergoes broad data training, typically through self-supervision at scale, and can be adapted or fine-tuned for a wide range of downstream tasks. The concept of a foundation model encompasses its ability to serve as a versatile and adaptable tool across various applications.
As of writing this (summer 2023), many LLMs are fine-tuned to be instructional or conversational — primarily for human-computer interaction improvement. Fine-tuning is collecting task- or domain-specific data and using it to train the foundational model to make it more specialized for a task or allow for outputs of a particular format.
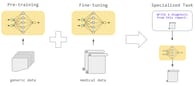
The weights of the model and its number of layers might change to incorporate this additional data.
For instance, ChatGPT is a fine-tuned chat model based on the foundational GPT-3.5 model and allows for prompting in the form of a dialogue. Instructional-tuned models allow to exploit the property of the LLMs of being a few-shot learner system for transfer learning: it is enough to show several input-output examples in the prompt, and the model will follow the desired output format for the next inputs.
Here are some examples of typical prompts to a foundation/chat/instructional models, left to right:

Local models
Most of the 2022 LLM race was "who has the largest model," with model sizes reaching hundreds of billions of parameters:

Things changed in early 2023 when Meta presented LLaMA — a much smaller LLM (1 order of magnitude less in the number of parameters compared to GPT-3 and later OpenAI models). Most importantly, LLaMA could run on a single GPU with comparable performance to GPT-3.
LLaMA official release was without the model weights and only included the code to run the model and reproduce experiments and examples. Anyone interested in getting model weights needed to join the waitlist. However, the weights were leaked on 4chan, and within a few days, tech enthusiasts posted tutorials on how to run LLaMA locally on a Windows PC, a M1 Mac, a Google Pixel smartphone, and a Raspberry Pi.
The need for a commercially-usable solution gave birth to several variants of local LLMs, which we briefly review below.
LLaMA family
Meta AI develops the LLaMA family of LLMs. The key assumption behind this model was that more training data — and not a larger model in terms of number of parameters — is a key to better LLM performance. It proved correct, and LLaMA could outperform models almost x100 of its size.
Meta released the complete LLaMA 2 family of models with weights about 6 months later, and this version is available for free for research and commercial use. LLaMA 2 most closely matches GPT-3.5 if we compare the benchmark performance:

As the development team notes: "LLaMA 2 models are trained on 2 trillion tokens and have double the context length of LLaMA 1. LLaMA-2-chat models have additionally been trained on over 1 million new human annotations."
Apart from the double context size, the biggest change from LLaMA is a very permissive license of LLaMA 2 that enables commercial use immediately.
Alpaca
In a month after the LLaMA release, Stanford CRFM/HAI researchers fine-tuned LLaMA 1 to a conversational model called Alpaca for USD 600:
- USD 500 went towards synthetic conversational data generation with OpenAIs models, and
- USD 100 towards cloud GPU rental for the actual training

Basically, Alpaca to LLaMA 1 is what ChatGPT is to GPT-3.5.
RedPajama
In parallel to Alpaca development, a collaboration of several open-source AI community member organizations (Ontocord.ai, ETH DS3Lab, AAI CERC, Université de Montréal, MILA - Québec AI Institute, Stanford Center for Research on Foundation Models (CRFM), Stanford Hazy Research research group, and LAION) led by Together.ai successfully reproduced LLaMA from scratch.
The first major independent contribution was a 5TB dataset of over 1.2 trillion tokens, which others have used to train even more models like MPT, OpenLLaMA, or OpenAlpaca.
| Dataset | Token Count |
|---|---|
| Commoncrawl | 878 Billion |
| C4 | 175 Billion |
| GitHub | 59 Billion |
| Books | 26 Billion |
| ArXiv | 28 Billion |
| Wikipedia | 24 Billion |
| StackExchange | 20 Billion |
| Total | 1.2 Trillion |
The collaboration also presented 6 models — the foundation and instruction/chat fine-tuned options in the sizes 3B and 7B parameters.
As the collaboration notes: "... the training was done on 3,072 V100 GPUs provided as part of the INCITE 2023 project on Scalable Foundation Models for Transferrable Generalist AI, awarded to MILA, LAION, and EleutherAI in fall 2022, with support from the Oak Ridge Leadership Computing Facility (OLCF) and INCITE program."
Together.ai also provides an interactive fine-tuning cost estimate calculator on their website, now also listing the LLaMA 2 models.
OpenLLaMA
OpenLLaMA is an LLM open-sourcing effort from Berkeley AI Research that relies on the RedPajama dataset and also replicates the LLaMA training procedure.
The v1 models are trained on the RedPajama dataset, while the v2 models are trained on a combination of the Falcon refined-web dataset, the StarCoder dataset, and the RedPajama dataset's portions from Wikipedia, arXiv, books, and StackExchange. The datasets appear to consist of approximately 1 trillion tokens in size.
OpenLLaMA exhibits comparable performance to the original LLaMA and comes in 3B, 7B, and 13B sizes.
MPT
MPT family of transformer LLMs trained from scratch on 1T tokens of text and code.

It is open source, available for commercial use, and MPT-7B matches the quality of LLaMA-7B and was trained on the MosaicML platform in 9.5 days with zero human intervention at a cost of ~$200k.
The competitive advantage of this model is the large context size of 65k+ tokens, which, as of writing this, is not available within the latest GPT-4 model of OpenAI, which has 32k tokens context.


MPT is developed by MosaicML, an open-source startup with neural network expertise that has built a platform for organizations to train large language models and deploy generative AI tools based on them. The company said that its latest release, MPT-30B, "has showcased how organizations can quickly build and train their own state-of-the-art models using their data in a cost-effective way." The company was recently acquired by Databricks.
GPT-J (and Dolly)
GPT-J is yet another open-source LLM of the transformer architecture and a competitor to GPT-3, trained on the Pile dataset.
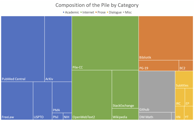
It is developed by EleutherAI, a non-profit AI research lab that focuses on interpretability and alignment of large models.
The competitive advantage of this model is its size — with only 6B parameters, it is still competitive with much larger models like GPT-3-175B.
As Wikipedia puts it, "GPT-J-6B performs almost as well as the 6.7 billion parameter GPT-3 (Curie) on a variety of tasks... It even outperforms the 175 billion parameter GPT-3 (Davinci) on code generation tasks... With fine-tuning, it outperforms an untuned GPT-3 (Davinci) on a number of tasks."
In March 2023, Databricks released Dolly, an Apache-licensed, instruction-following model created by fine-tuning GPT-J on the Stanford Alpaca dataset.
Licenses
| LLM | Model type | Model sizes | Training corpus size, tokens | License | Commercial application |
|---|---|---|---|---|---|
| LLaMA | Foundation | 7B, 13B, 33B, 65B | 1T | LLaMA LICENSE AGREEMENT | 🚫 |
| LLaMA-2 | Foundation, Chat | 7B, 13B, 70B | 2T | LLaMA 2 License Agreement | ✅ |
| Alpaca | Chat | 7B | - | LLaMA LICENSE AGREEMENT | 🚫 |
| RedPajama | Foundation, Chat | 3B, 7B | 1.2T | Apache 2.0 | ✅ |
| OpenLLaMA | Foundation | 3B, 7B, 13B | 1T | Apache 2.0 | ✅ |
| MPT | Foundation, Instruct, Chat, StoryWriter (up to 84k context) | 7B, 30B | 1T | Apache 2.0 | ✅ (except the Chat models) |
| GPT-J | Foundation | 6B | 0.4T | Apache 2.0 | ✅ |
Running models
LLaMA 2, as of now, is one of the most powerful language models, available for free for research and commercial use. So, we take it as a baseline in our practical part and will compare it with a few open LLMs in terms of generation quality. We will also compare it with OpenAI's models for computation costs.
Before we proceed, let's review some crucial concepts for the practical use of such models on consumer-grade electronics.
Quantization
It is important to remember that under the hood, it is all huge matrix multiplication, so we care most about the efficiency of basic arithmetic operations and memory space to store all those numbers.

The size of a model is determined by the number of its parameters and their precision, typically represented as float32, float16, or bfloat16.
To calculate the model size in bytes, we multiply the number of parameters by the chosen precision's size in bytes.
For instance, with the bfloat16 version of the BLOOM-176B model, we have 176 billion parameters, resulting in
Quantization in machine learning refers to the conversion of data from floating point 16 or 32 bits to a lower precision format like integer 8 bit. This process involves performing critical operations, such as Convolution, in integer precision, and then converting the lower precision output back to higher precision in floating point representation. By optimizing the precision of the data, quantization helps improve efficiency and performance in ML models.

Utilizing lower-bit quantized data minimizes data movement, both on-chip and off-chip, leading to reduced memory bandwidth and significant energy savings. By employing lower-precision mathematical operations, such as an 8-bit integer multiply instead of a 32-bit floating point multiply, energy consumption is reduced, and compute efficiency is increased, resulting in lower power consumption. Additionally, reducing the bit representation of the neural network's parameters results in decreased memory storage requirements.
Modern quantization methods allow to minimize LLM output quality degradation while allowing to run them on consumer-grade devices. In some cases (like below), we can do so without using the parallel processing capabilities of GPUs and vRAM, and relying only on CPU and RAM.
LLM playground options
Apart from the Huggingface hub, there are some dedicated web playgrounds to test out open LLMs:
-
LLaMA 2 Chat in all 3 sizes at the Perplexity Labs
-
GPT-J-6B Chat at the Eleuther AI model text page
There are several ways to run LLaMA (and other) models with zero or minimal configuration, just out-of-the-box:
- a desktop app by Faraday.dev, or
- a NodeJS package dalai
And there are several options for a minimal build-and-run workflow:
- ollama if you are interested in a web interface to run models from LLaMA family
- text-generation-webui, openplayground are web interfaces that support building and running different model backends
- llama.cpp and its forked/related setups, to run it interactively in the Terminal
- pyllama hacked version of LLaMA based on original Facebook's implementation but more convenient to run on a single consumer grade GPU
- alpaca-lora if you want to build and run instruct-tuned LLaMA on consumer hardware
Local CPU inference
Here is a brief summary of comparing generation quality for a few open LLLMs that we did:
| Model | Size | Setup | Inference | Precision | Laptop |
|---|---|---|---|---|---|
| LLaMA | 7B | llama.cpp | CPU | int4 | Apple M1 Pro 16G RAM |
| LLaMA 2 | 7B | llama.cpp | CPU | int4, f16 | Apple M1 Pro 16G RAM |
| LLaMA 2 | 70B | llama.cpp | CPU, GPU | int4 | Apple M1 Pro 16G RAM, Apple M2 Pro 32G RAM |
| RedPajama-INCITE-Base | 7B | redpajama.cpp | CPU | int4 | Apple M1 Pro 16G RAM |
| MPT | 7B | ggml | CPU | int4 | Apple M1 Pro 16G RAM |
| GPT-J | 6B | ggml | CPU | int4, f16 | Apple M1 Pro 16G RAM |
This local zoo takes 225G of the disk space if for each model you store the full and the quantized model versions.
Important, that using Metal allows the computation to be executed on the GPU for Apple devices. If you want to know more about how llama.cpp works, you can check out this explainer.
You can also investigate ggml repository from the same author.
It's a tensor library for machine learning that written in C and optimized for Apple Silicon, and a foundation for llama.cpp.
So, let's finally run some models?
LLaMA
MacBook Pro M1 16GB, macOS Ventura
LLaMA, 7B
LLaMA 2, 7B
LLaMA 2, 7B, F16
RedPajama
MacBook Pro M1 16GB, macOS Ventura
RedPajama-INCITE 7B
MPT
MacBook Pro M1 16GB, macOS entura
MPT 7B
GPT-J
MacBook Pro M1 16GB, macOS Ventura
GPT-J 6B F16
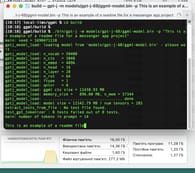
CPU+RAM VS GPU+Metal: LLaMA 2 70B
Now let's switch to the MacBook Pro M2 Max with 32 GB RAM and 12 total cores (8 performance and 4 efficiency). If we run LLaMA 2 70B like other models, we get the error of failing to load the model. Below, we can see the Terminal window with the main execution command to run the LLaMA 2 70B model and the error as a result.
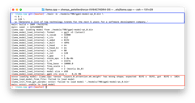
To fix this error and run model we need to add -gqa 8 parameter to main execution command.
If you want to know more about it, you can dive deep into this issue on GitHub.
After updating our main execution command, we can see that Llama 2 70B is working. You can see below the corresponding screenshot.
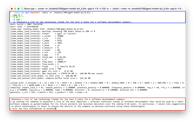
We want to know which option is better for a local device to run Llama 2 70B: CPU+RAM or GPU+Metal. See the videos below for each configuration.
Llama 2 70B running using CPU+RAM
The original video was 22 minutes. We speed up it to 20x faster.
Llama 2 70B running using GPU+Metal
The original video was 25 minutes. We speed up it to 20x faster.
As you can see, using LLaMA 2 70B on MacBook Pro M2 Max is better with GPU+Metal configuration.
Prompt comparison
We will compare LLaMA 2 and OpenAI model performance using three prompts with generation, translation, and summary actions.
Prompt 1
Generate a list of top technology trends for the next 5 years for a software development company.
ChatGPT 3.5
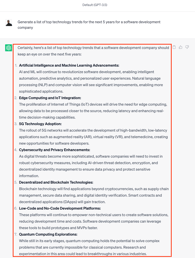
Llama 2 7B
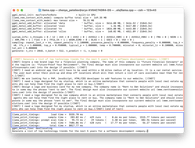
Llama 2 7B Chat
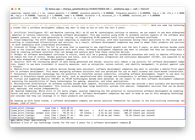
Llama 2 13B
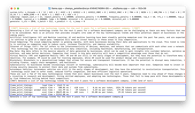
Llama 2 13B Chat
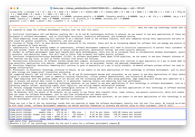
Prompt 2
Take this text "In Technological R&D we generate new knowledge and out-of-the-box ideas
that the company can use to create new tech, products, or approaches or improve existing
initiatives." and translate it into Ukrainian.
ChatGPT 3.5

Llama 2 7B

Llama 2 7B Chat
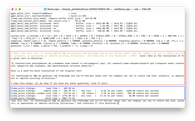
Llama 2 13B

Llama 2 13B Chat
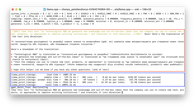
Prompt 3
Summarize the following text "We’re working hard to be in the avant-garde of software
technology and to be aware of the future. We don't limit ourselves by borders of any
sort, not even our imagination. We want to see beyond our regular domain.
When doing research, we don’t know what we may find in the end. Will it be a breakthrough
or a disappointment? We never know. Thus, we’re also learning to fail and accept our
failures. These failures then form the deep-rooted substratum that yields our
future discoveries.
While doing our work, we aspire to foster MacPaw’s innovation culture. Our insights
can serve as proof of concept for our friends’ unconventional ideas to be
later implemented in our products."
ChatGPT 3.5

Llama 2 7B
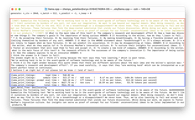
Llama 2 7B Chat

Llama 2 13B

Llama 2 13B Chat

How much is the prompt?
It's exciting to calculate how much is the prompt cost. We must clarify that we will calculate the cost of 1K output tokens. In general, 1K tokens is about 750 words in English. We will compare a SaaS solution like using OpenAI API with one based on maintaining local LLMs. So, let's begin!
Reference: OpenAI API
We will use as a baseline the GPT-3.5 Turbo model because it has a similar context to LLaMA 2 models. GPT-4 model is much more powerful than others, and the comparison will not be adequate. You can find actual pricing for different OpenAI models here.
See below the current pricing for the GPT-3.5 Turbo model:
| Model | Input | Output |
|---|---|---|
| 4K context | 0.0015 USD / 1K tokens | 0.002 USD / 1K tokens |
| 16K context | 0.003 USD / 1K tokens | 0.004 USD / 1K tokens |
For our investigation we used price for tokens on output:
| Model | Output |
|---|---|
| 4K context | 0.002 USD / 1K tokens |
Scenario 1: renting cloud power
Target
Run a local LLM in the cloud.
Theory
We will use a M1 MacBook Pro with 16GB RAM as a proxy to run the model and ensure that it works correctly Then, we will find similar device configuration for renting cloud power and calculate cost of 1K tokens.
Limitations
We have only 1 query at a time, nothing is parallelized.
Practice
We run LLaMA 2 7B with 4K context on CPU using RAM with llama.cpp.
You can see below resource use and generation speed:
llama.cpp: loading model from models/7B/ggml-model-q4_0.bin
llama_model_load_internal: format = ggjt v3 (latest)
llama_model_load_internal: n_vocab = 32000
llama_model_load_internal: n_ctx = 4096
llama_print_timings: load time = 7529,09 ms
llama_print_timings: sample time = 672,13 ms / 866 runs (0,78 ms per token, 1288,43 tokens per second)
llama_print_timings: prompt eval time = 1878,48 ms / 15 tokens (125,23 ms per token, 7,99 tokens per second)
llama_print_timings: eval time = 30151,76 ms / 865 runs (34,86 ms per token, 28,69 tokens per second)
llama_print_timings: total time = 32795,35 ms
While running, the model used 12 GB RAM. Let’s see how much it will cost to rent a GPU with similar performance. We will use this resource for GPU Cloud Server Comparison. This website contains a table with different cloud server configurations and prices. For example:

A similar device configuration for the reference M1 MacBook Pro is AWS with K80 (12 GB) GPU Type. It consists of 1 GPU with 12 GB GPU RAM. Let's calculate the cost of 1K tokens.
There are 3600 seconds in an hour. Using our cloud server AWS K80 (12 GB) with 1 GPU (12 GB) costs 0.90 USD/3600s.
We will use 28 tokens per second as a default speed. Let's calculate how many tokens our model can produce per hour: 28 * 3600 = 100 800 tokens per hour (disregard prompt, output, any other time).
So, our model can produce 100800 t/hour, and renting cloud power is 0.90 USD/hour. Let's find out how much it costs to generate 1000 tokens:
Price of 1000 tokens = 0.90 USD/hour * 1000 t / (100800 t/hour) = 0.008928571429 USD.
Remember that we considered a LLaMA 2 7B model. We assume that running a larger Llama 2 70B model will not be cheaper, so our numbers serve as a lower bound on the cost.
To sum up, renting the cloud for the Llama 2 7B model is x4 more expensive than the OpenAI Saas solution, which costs $0.002 / 1K tokens.
Scenario 2: building our own server
Target
Run a LLM on our own server.
Theory
First of all, we need to understand that the significant cost components for this scenario are:
- electricity consumption
- hardware (the graphic processor)
We want to build our own server and find a device configuration to run the LLaMA 2 70B model. Then, we will calculate the cost of 1K tokens.
Limitations
- We have only 1 query at a time; nothing is parallelized;
- We disregard other costs (other hardware, maintenance, human ML expertise, web access);
- We consider running on GPU — so not through llama.cpp on CPU.
Practice
After surveying the practitioner experiences on thematic forums, we have found this post specifying that to want to run LLaMA 2 70B locally on a server, we need to use NVIDIA GeForce RTX 3090 (4090) graphic processors with GPU RAM 24 GB. The average price for it is 2000 USD. But we need two graphic processors at least to fit the model, so GPU hardware costs rise to about 4000 USD.
Let's find out how much it costs to generate 1000 tokens using our own server. In the same above post, the author said about the token generation speed: "Both cards are 24gb, I'm using 14gb on first card and 20 on second, and getting 9t/s".
We want to calculate how much time our server would need to generate 1K tokens. For simplicity, let's round numbers up as 9t/s ~ 10t/s, and then 1000t/100t/s = 100s ~ 2 minutes. Our server can generate 1K tokens per 2 minutes.
Next, electricity consumption for NVIDIA GeForce RTX 3090 is 360 W-h/h. Remember that our server consists of two graphic processors at least. So, total electricity consumption is 2*360 W-h/h. To generate 1K tokens, we will consume 0,72 kW-h/ 3600 s * 100 s = 0,02 kW-h.
What about electricity prices? We take average Kyiv region price 5000 UAH / MW-h or 5 UAH / kW-h. Let's convert it to USD. Assuming the exchange rate as 1 USD = 36.90 UAH, the electricity price is 0,136 USD / kW-h.
In this case, generating 1K tokens will cost 0,02 kW-h * 0,136 USD/kW-h = 0,00272 USD.
Solution price comparison
Let's sum up and put the results in a table:
| Solution | Model | Price of 1K tokens |
|---|---|---|
| OpenAI | GPT-3.5 Turbo | 0.002 USD |
| Renting cloud power | LLaMa 2 7B | 0.0089+ USD |
| Building own server | LLaMa 2 70B | 0.0027+ USD |
We would like to remind you that it is correct to compare Meta’s LLaMA 2 70B with OpenAI’s GPT-3.5 Turbo. Meta’s LLaMA 2 7B model is simpler and much smaller (but runs on a modern laptop), so comparing it with OpenAI’s GPT-4 is not correct.
We came to the conclusion that with the current pricing policies, using OpenAI is cheaper than renting cloud power and building our own server.
Conclusion
Local language models (LLMs) hold great promise, particularly those with commercial licenses. The future of this technology looks bright, especially with the news about the potential use of local LLMs on smartphone devices, and industry interest in developing dedicated chips.
Currently, there is a surge in interest in this tech, resulting in high demand for hardware, which significantly affects prices. OpenAI's current pricing policy makes it an appealing choice for the short and medium term. However, for long-term considerations such as data privacy, local LLMs may soon become a more attractive and competitive option.
Potential integrations
Any product that uses the OpenAI API could in theory use a self-hosted instance.
Links
LLM basics
A jargon-free explanation of how AI large language models work
Large Language Models 101: History, Evolution and Future (image 1 source)
The Full Story of Large Language Models and RLHF
Zero-/1-/Few-shot learning
Brown, Tom, et al. "Language models are few-shot learners." Advances in neural information processing systems 33 (2020): 1877-1901. arXiv preprint
Zero-Shot, One-Shot, Few-Shot Learning
LLaMA
Touvron, Hugo, et al. "Llama: Open and efficient foundation language models." (2023) arXiv preprint
Touvron, Hugo, et al. "Llama 2: Open foundation and fine-tuned chat models." (2023) arXiv preprint
Llama 1 vs Llama 2 AI architecture compared and tested
Open LLMs
Open-LLMs - A list of LLMs for Commercial Use