Ivan Petrukha Senior Research Engineer
Instant detection of phishing websites on your Mac. Yes, it's possible.

- #macOS
- #Moonlock
• 8 min read
Phishing scams dupe thousands of unsuspecting victims every year, with millions of dollars lost to ruthless criminals. Last year alone, an estimated five million unique phishing pages were published online.
Although there are a bunch of antiphishing apps on the market, most rely on blacklists, web crawlers, and external servers for processing. These demand processing power, time, and large amounts of data to learn. Meanwhile, with each minute cybercriminals are evolving their methods to avoid detection.
Recognizing the dangers of phishing, MacPaw’s cybersecurity division, Moonlock, has developed a prototype app that runs locally on macOS, independent of browsers, and checks webpages for phishing within seconds. Technological R&D has taken the reins to improve the prototype and tailor it to each Mac user. After all, that's what we do at MacPaw — making Mac life better and safer.
Why current detection methods need improvements
Website spoofing is a common tactic for cybercriminals to steal data. These websites act, look, and feel like companies we trust but were designed to trick people into giving away their sensitive information. The chances of falling victim to this type of phishing are high because criminals manipulate search engines to push fakes to the top of search results.
From what we see, current antiphishing apps lean on three common detection methods: blacklisting, machine learning, and reference lists. All of them have their advantages, and all need further improvements. Let's have a look at them.
Blacklisting: effective but slow to update
Blacklisting is a commonly used security feature in all modern web browsers. For example, Google Safe Browsing uses lists of known phishing website addresses or domains. When a user attempts to visit a website, the system checks the website address against this list. If there is a match, access to the website is blocked, and the user gets a warning about the potential danger.
The blacklisting method is known for being fast and straightforward. It can quickly identify known threats and is easy to set up and understand. However, it's often ineffective because new phishing websites can take a while to get on the list, while attackers complicate detection and frequently change website URLs to avoid being detected.
Machine learning: lacks accuracy
Machine learning helps analyze webpage features. It looks at URL structures, HTML content, and metadata to determine whether a website is spoofed or legitimate.
This method works well for browser extensions, learning from user data to detect new and unknown phishing sites. However, it has drawbacks: machine learning requires complex algorithms and lots of training data, and cybercriminals change their techniques to hide malicious content very fast. These challenges lead to lower accuracy, making it unsuitable for standalone security products.
Reference-based approach: it could be faster
This method is praised for its accuracy. It effectively identifies phishing sites that visually mimic real ones. Even though analyzing visual content requires significant processing power and time, reference-based detection has successfully worked in the latest antiphishing apps.
Here, computer vision analyzes and compares webpages against a reference list of known trustworthy websites. It breaks down the image on a screen to distinctly identify and distinguish components like text, icons, and context.
For some, the cons of this approach lie in its reliance on automated web crawling to update lists of malicious websites (PhishIntention, Phishpedia, and VisualPhishNet). Others are cloud-first (DynaPhish and KnowPhish), meaning they take up many computational resources.
How we detect a fresh phishing website within a second
We chose to advance the reference-based method to warn users about phishing websites even if they have appeared on the web just seconds ago. We eliminate cloud processing and move all computations locally on-device, improving performance and enhancing security, while ensuring all user data stays on the device.
Here's a brief peak under the hood of our antiphishing prototype.
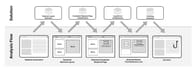
See what we have on the webpage
First, we identify key webpage elements like logos, input fields, and buttons to get a clear picture of the page layout. After testing various models, we chose DETR with ResNet-50 for its accuracy and performance.
By analyzing screenshots and identifying layout elements, the model determines if the webpage has credential input forms and finds the brand logo area. It uses Non-Maximum Suppression (NMS) to remove redundant or overlapping boxes, improving detection accuracy.
Attribute the webpage to a brand
Next, we classify the detected logos to see if they match any well-known brands. We then compare the webpage URL against the reference list of real websites.
Netify helped us get primary domains for our detectable brands, and we added some manually. During the process, we realized why cybercriminals are so successful with phishing. Brands often create networks of official domains for marketing, so it’s hard for people to stay alert of spoofed websites. DHL, for example, has dhl.com, express.dhl, mydhli.com, dhlsameday.com, dhlexpresscommerce.com, and they are all official!
Now, we can compare a webpage URL with a whitelist of known web addresses. If the website is official, we can skip all further steps. In the screenshot below, the model correctly identifies the Netflix logo and notifies users that it’s safe to browse.
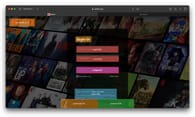
Check for credentials input fields
Finally, we check if the webpage requires credentials. If it does, the URL is wrong, and the webpage logo matches a known brand, it's likely a phishing attempt.
We used features already extracted from the first step to save disk storage and RAM consumption. The DETR model inputs the query image and generates N output vectors. These vectors predict the class and location of objects, providing detailed information for object-level image representation.
We then divided this backbone into two models: the LayoutFeatureExtractor, which generates shape features, and the LayoutObjectDetector, which takes these features as input and predicts the bounding boxes. Next, we froze the feature extractor to prevent weight changes and trained a simple multilayer perceptron to transform the extracted features into an output of shape containing scores for credential or non-credential classes.
In the screenshot, our layout classifier confirmed it's a page with credential input fields and a DHL logo. However, we're not on the official DHL website, so naturally, the prototype warns about a spoofed page!
Building and testing our app
We created a fully native macOS app using Swift and CoreML, Apple's machine learning framework. This way, our prototype runs in the background, continuously protecting Mac users from phishing websites without draining their system resources.
To ensure the application works with all browsers, we implemented a Region of Interest technique using the macOS Accessibility framework. This framework primarily helps people with disabilities, but to our surprise, we can use Accessibility metadata and achieve remarkable improvements in antiphishing models, too.
The accuracy
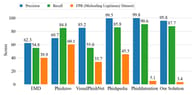
Overall, our system matches or improves baseline accuracy. In layout detection, our Mean Average Precision (mAP) is slightly lower than PhishIntention but matches Phishpedia. Despite lower accuracy, our solution processes faster. Logo recognition accuracy reaches 90.8%, and credential input detection accuracy is 98.1%.
The graph below compares our performance to other methods, highlighting our strengths in precision, recall, and false positive rate. We detected 87.7% of phishing cases and kept the false positive rate as low as 3.4%.
Processing power consumption
Our final metrics show that our solution runs smoothly in the background without a noticeable impact. The CPU usage is just a small part of the total capacity: with 8 cores in Apple M1, we're using 16% of the 800% available. This level of consumption is similar to three active Safari tabs or one Zoom call.

Final thoughts
We've proven that modern Mac computers can efficiently run machine learning models locally, keeping things speedy while saving resources. In particular, our work shows how on-device macOS systems can immediately spot phishing websites that harvest credentials from people.
Even though we focused on detecting spoofed web pages, we can do more with this technology. We can apply it to email clients to warn about phishing emails. We can integrate it into messaging apps to detect smishing. A completed solution is so versatile that it might blend different algorithms and eventually become the ultimate protection from social engineering attacks.
This article is based on the 2024 position paper "Think Globally, React Locally - Bringing Real-time Reference-based Website Phishing Detection on macOS" by MacPaw specialists Ivan Petrukha, Nataliia Stulova, and Sergii Kryvoblotskyi that was accepted to STAST'24, 14th International Workshop on Socio-Technical Aspects in Security, affiliated with the 9th IEEE European Symposium on Security and Privacy (Vienna, Austria, 12 July 2024).
Access the full research here: https://arxiv.org/pdf/2405.18236.