Vlad Hamolia Senior Data Scientist
Federated Learning Basics

- #Machine Learning
• 7 min read
Introduction
We live in a world where data privacy is becoming increasingly valuable. More and more people are becoming concerned about potential data breach risks, malware attacks, and tracking technologies. To address user complaints about unwanted tracking, software developers devote tremendous efforts to adapting their products according to user security demands. Those who don't follow the security and data protection standards, like SOC 2, move to a precarious position for the rest of the world. In the age of Big Data, when everything has to be data-driven, this creates an issue.
This prefix applies to nearly every function in our professional and personal lives. Buzzwords aside, data is central to the jobs of marketing professionals and product managers, who leverage it to bolster their decisions, generate new ideas, and, ultimately, create a better experience for users. However, having data that you can make sense of, have confidence in, connect to the rest of your systems, and access effortlessly and quickly is easier said than done.
One opportunity to do so is federated learning, an approach where we can utilize most of the user data for machine learning (ML) training right on the user's device. Since we all can use the advantages of ML, like fraud detection and autonomous driving, we want this field to flourish and help us automate even the most essential tasks without compromising security. The problem is data accessibility, and federated learning seems to solve this problem.
Federated learning systems
The development of a conventional ML model begins with initial data revision with an element of descriptive analysis that helps to define, show, or summarize data points. But even before that, we need to legally collect the data, store it, and grant processing permissions to a narrow circle of people. The biggest issue is data collection because each business has to follow the latest regulatory standards. These standards question how much information a company knows, collects, and utilizes about its end users.
Federated learning seems to be a workaround since it solves most of the problems with privacy for both businesses and end-users. It is a ML technique that allows a data scientist to analyze and train ML models without sharing and storing raw user data. In Federated learning, a remote server coordinates the end-user devices (nodes), and each node contains a set of available training data items prohibited from sharing directly. In contrast to a conventional ML pipeline, federated learning allows one to train local models directly on the users' devices and share only the model parameters with businesses, resulting in more optimal communication costs and ensuring user privacy.
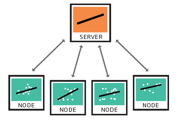
Setup and training
To set up a federated learning system, you need to have the following:
- permissions to access the data of interest on the user's device
- a ML model that can be trained on this data
- a server that can average models trained on user data
- an infrastructure that allows transferring the training artifacts between the server and the user devices
There are 5 main steps in the model training process:
- The central server deploys code that prepares all required data for training, meaning a ML model, to user devices, acting as computational nodes.
- The server selects the nodes ready to be trained (the device has the correct version of the ML model, and the user data is collected).
- The server distributes the initial ML model weights to the available nodes.
- The nodes are trained locally with their data.
- Each node sends a locally trained model back to the server to average those models and transmit back the final model to the nodes.
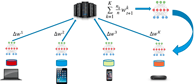
At the end of this process, we'll have a trained final model built out of thousands of individual models (depending on the number of user devices used in its training) without sharing any sensitive data from the user device.
Traditional machine learning VS federated learning
To compare conventional ML and federated learning approaches, let's select one ML hypothetical task as an example, building a smart keyboard that predicts which word the user will type next.
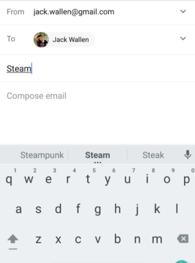
In a traditional ML workflow, the user data is centralized in a single place to do model training, for instance, in a separate database that collects the user's typing data and posts it daily. Using a query language, like SQL, a data scientist with prior knowledge of the data origin extracts all available data from the existing database. In this setup, the whole data set is available in one place, and it is possible to experiment with it, test hypotheses, train different ML models, and more. With all this information, it is possible to build not only a word prediction but also some typing correction or emoji suggestion models only because this information is easy to obtain and process from our database.
Federated learning uses a bottom-up approach that starts with task formulation, like "We need to predict which word the user will type next." After that, data selection for the task is performed, for instance, choosing only the data from what users type on their keyboards in messengers but not passwords or any sensitive data. Once we establish the format and the sources of the required data, we need to (a) select the model that will meet the predefined input and (b) build an infrastructure that will deploy the ML model to each device. Then we synchronize those devices with the model parameter server, sharing a locally trained model (not a subset of the user data!). Once multiple users send their trained modes to the server, they will receive an updated ML model averaged on the data from all users.
At first glance, federated learning is a complicated approach that requires way more effort on the ML modeling and infrastructure setup. However, the most significant advantage of federated learning is using sensitive data without compromising the user. Usually, if you approach your project manager and ask to collect everything users type on their keyboards, you'll likely be rejected with reference to the GDPR policies. Federated Learning lets you deal with it.
Applications
The field of application for federated learning is vast. For instance, it can help personalize marketing campaigns to users' behavior and device usage patterns. Uplift modeling can increase user engagement, app use duration, and module usage in the scope of the app. Finally, custom-tailored user flow becomes an option since we have all data on the user device, and we can train the model to learn how to select app flow for the end-user (concerning the target metrics, like conversion).
Several top companies have already been using federated learning for a while now:
- Google has shared the result of a distributed model training for their Google keyboard.
- Apple published its research on detecting the most popular domains loaded on the Safari browser.
- Amazon AWS already has a tech stack for federated learning infrastructure that covers all the stages in the training process.
Conclusion
There are numerous privacy-enhancing techniques like federated learning, for example, homomorphic encryption and differential privacy, each deserving a separate article.
Even though federated learning is a relatively new approach that requires some effort on the infrastructure setup, it deserves more attention since it opens many new opportunities for preserving user privacy.
Links
https://machinelearning.apple.com/research/learning-with-privacy-at-scale