Volodymyr Tochytskyi Engineering Manager
Implementing Incident Management for Rapid Recovery

- #Outage
- #SRE
• 15 min read
Imagine owning a company that sells airline tickets online. Suddenly, your main website crashes, becoming completely unresponsive. This is a huge blow to your business, both in terms of reputation and revenue. Customers can neither book flights nor check in online.
Now, what’s going on behind the scenes? Amidst the chaos, some employees are resorting to jokes and coffee breaks, while most await a resolution from someone else. Managers are frantically trying to find a quick fix, reaching out to anyone who can help.
Developers, overwhelmed by the urgency, struggle to debug effectively. Meanwhile, customers are left in the dark, unsure about when the website will be operational again. As time ticks, your business is losing money.
Let’s face it: going into a crisis is scary. But it doesn’t have to be overwhelming. In this article, I will guide you through developing an effective incident management strategy, outlining potential consequences and offering practical solutions.
How incidents affect a company
Downtime can have a cascading effect across different areas of operation.
Security
There is a risk of data breaches or security vulnerabilities being exploited, potentially compromising sensitive information and leading to legal problems.
Reputation
Customer support teams may face a surge in inquiries and complaints, straining resources and impacting overall customer satisfaction. The negative publicity resulting from a prolonged outage can dilute the company’s image for reliability.
Penalties
In some cases, contractual penalties may apply if reliability agreements are not met, causing financial losses.
Employee burnout
From an employee's perspective, the urgency to fix incidents "ASAP” can create intense pressure, which might lead to burnout and lower job satisfaction.
Lost revenue
It's clear that a broken product won't generate revenue. With each minute of the outage, financial losses only increase.
Cost of downtime
Did you know that the average cost of downtime is $5600 per minute? That’s according to Atlassian, a juggernaut in indecent management. The cost can differ depending on the type of business.
The formula to calculate downtime cost per hour is often as follows:
Cost = Lost Revenue + Lost Productivity + Recovery Costs + Intangible Costs
- Lost Revenue: The income the organization would have generated during downtime.
- Lost Productivity: The cost of employee wages during downtime, when they're unable to conduct productive work.
- Recovery Costs: Money spent to fix the issue and restore normal operations, including technical support and equipment.
- Intangible Costs: Effects on the organization's reputation, customer trust, and employee morale.
To better understand the consequences of downtime, let's look at some famous examples.
Delta Air Lines
In 2016, Delta Air Lines, a major American airline and a legacy carrier, suffered a 5-hour power outage that caused thousands of flight cancellations and cost an estimated $150 million in lost revenue.
Amazon
Amazon experienced an outage on Prime Day in 2018, costing up to $100 million per hour in estimated lost sales. Some customers couldn’t complete purchases on the website, and some threatened to cancel Prime subscriptions.
Knight Capital
In 2012, Knight Capital, an American global financial services firm, experienced a software glitch that resulted in a 45-minute trading outage. This single incident reportedly cost the company $440 million in trading losses.
In 2019, a widespread blackout affected millions of Facebook users, resulting in losses of nearly $90 million. This downtime also impacted other associated products, including Instagram, Messenger, and WhatsApp, and lasted for a minimum of 14 hours.
Solution – Outage management plan
Considering the cascading damages associated with downtime, every software company needs a well-defined outage management plan. However, simply having a plan is not enough. The most crucial part is the ability to apply it effectively in critical situations – another reason to make it specific to your context.
When creating your outage management plan, the best practice is to structure it around these core elements: Detect, Respond, Recover, Learn, and Improve.

They can be in the form of a playbook or code of conduct; the most important thing is to make them accessible and grounded to your specific needs.
Let’s take a closer look.
Detect
Start by defining what is an incident for your company. For example, is 10 errors per hour on a website a problem that requires immediate attention? Establish clear criteria for identifying and categorizing events that may disrupt normal business operations. The following frameworks and tools can help.
Service level framework
Key concepts related to detecting incidents include the Service level framework that consists of Service Level Agreements (SLA), Service Level Objectives (SLO), and Service Level Indicators (SLI).
- SLA: A formal agreement with customers that sets service expectations, often including incident response and resolution times. SLAs manage customer expectations and provide a performance measurement framework. See SLA examples from Amazon Web Services (AWS).
- SLO: a specific, measurable target for the performance of a service. It is derived from the SLA and defines the acceptable level of performance. SLOs are crucial for monitoring and improving service quality.
- SLI: a metric that reflects the performance of a service. It is used to assess whether the service is meeting its SLO. SLIs can include response time, system availability, error rates, and other relevant metrics.
Typical service level framework in e-commerce
Let's look for an example of a service level framework for a typical e-commerce platform.
| Service Level | Definition | Metrics |
|---|---|---|
| SLA | The e-commerce platform commits to providing 99.9% uptime for its website and ensuring that customers can complete transactions without errors. | • Uptime: 99.9% • Transaction Success Rate: 99.5% • Response Time: The average response time for the website pages to load is less than 3 seconds. |
| SLO | Derived from the SLA, the SLO sets specific, measurable targets for each metric to ensure the desired service level. | • Achieve 99.95% uptime for the website. • Maintain a success rate of 99.8% for completed transactions. • Ensure that the average response time for website pages is less than 2 seconds. |
| SLI | The SLI represents the specific metric used to measure the performance of the service. | • Uptime: Percentage of time the website is operational. • Transaction Success Rate: Percentage of completed transactions without errors. • Response Time: Average time taken for a page to load on the website. |
Observability
You might be wondering how to know when your SLIs drop in performance. For that purpose, we apply an observability strategy, which encompasses practices like logging, monitoring, and alerting. While the detailed establishment of observability through best practices is a separate topic, it's worth showing how it looks in practice.
Monitoring tools
Grafana is a widely used monitoring tool, and it often presents complex dashboards filled with all sorts of data and charts. Greaaat... But what do we do with all that data? Which values are acceptable? Should we look at them every hour or once per day? What if there are numerous databases and even more infrastructure components to monitor?

When we apply a service-level framework, it is possible to visualize the whole system with several high-level graphics. They show the most vital metrics to answer the main question: “Is everything OK with a system?” Read more about that in Google’s book and how they use the so-called Golden Signals for that. Nowadays, it has become a common standard.
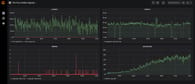
Ultimately, setting up automatic alerts based on Service Level Objectives (SLOs) can notify us of critical metric deviations. This way, we don't have to check the dashboard every hour or day, instead receiving automatic alerts in a messenger of our choice.

Respond
When we receive an alert or a customer complaint, the next step is to respond to a potential incident. The goal is to prevent or minimize the consequences. For that purpose, we should implement an on-call process, define target responsible roles, and describe incident levels. Moreover, we should always be ready to communicate effectively with employees and clients.
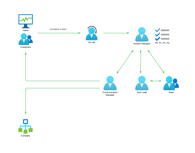
That’s quite a few should do’s out there. Let me explain.
On-call
On-call is a practice where team members take turns being available to respond to critical issues, including outside of regular working hours. Key aspects of it:
- Availability: on-call personnel must be reachable and ready to respond promptly, usually via phone, email, or other communication channels.
- Responsibility: on-call individuals are responsible for addressing specific issues or incidents during their designated on-call periods.
- Rotation: on-call duty typically follows a rotating schedule, distributing the responsibility across team members to ensure fair coverage.
Establish a communication plan to ensure that on-call personnel can be reached promptly. Include contact information, preferred communication channels, and any backup contacts. Use messaging apps, phone calls, or incident management platforms (e.g. Opsgenie).
Roles
During an incident, you cannot afford multiple people duplicating work; hence the need for clear roles and responsibilities. Everyone in the on-call team should understand available roles, associated duties, and who is assigned to what during an incident.
- Incident Manager holds the ultimate responsibility and authority, coordinates all response efforts, and covers all roles until they assign it to someone else.
- Tech Lead (aka On-Call Engineer/Subject Matter Expert) is often a senior technical expert, responsible for diagnosing issues, proposing solutions, and leading the technical team. They work closely with the Incident Manager.
- Communications Manager is a person skilled in public communications, possibly with customer support or PR experience. They handle internal and external communications about the incident.
Keep in mind that these roles are flexible and can be assigned to any team member. Additional roles can be defined by the company as needed.
Severity levels
As a next step of Response, Incident Manager, aided by others, determines the incident severity level, typically labeled as P0, P1, P2, or P3. "P" represents a classification system for incident severity or priority (similar to how the starting positions are referred to in Formula One). These levels guide response behavior, prioritization, and resource allocation. The exact definitions of each level may differ across organizations, but there's a general consensus on their meanings.
- P0: Critical incidents requiring immediate action, like critical system outages, data breaches, or major security issues, affecting many users or vital systems.
- P1: High-priority incidents requiring swift attention, such as major functionality problems, service degradation, or issues with significant financial consequences.
- P2: Medium-priority incidents that are less urgent than P0 or P1, including moderate functionality issues, service performance decline, non-critical bugs, or problems affecting some users.
- P3: Low-priority incidents with minor immediate operational impact, like minor functionality problems or user-specific issues.
The P0-P4 classification system is highly effective for directing the least necessary amount of organizational capability into responding to the incident, which can be crucial at times when you have several complex issues per day. For example, upon classifying an incident as P2 rather than P0, you save yourself from the need to urgently assemble a full-scale team intervention. The incident severity level practice saves time and resources, also giving you solid decision-making criteria.
Communicate
It is crucial to communicate updates internally via Communication Manager to avoid misunderstandings, work duplications, and redundant decisions. A great practice is to create a separate communication channel that displays incident communication with the ability to browse history in the future. For example, it can be a new channel in Slack #incident-ID, where ID is an incremental identifier of an incident in your company. All related staff will join this channel and will not disturb others.
Let’s not forget about communication with customers. Downtime can happen to the best of us, but providing live status is a good sign that you're in control. It’s certainly a better approach than letting users find out for themselves. So, don’t hide what’s happening.
Don’t just take my word for it. The biggest software companies do it.
GitHub
GitHub provides the current state at https://www.githubstatus.com/, and you can subscribe via email to details about an incident.
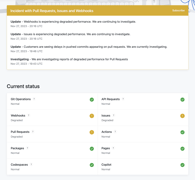
Cloudflare
A rising star in cloud hosting. It also use a status page https://www.cloudflarestatus.com/

Lots of companies inform customers this way because they know it's important.
Recover
The goal is to achieve a quick fix that restores your product to its normal working state. Here, you don’t think about the most sensible long-term solution. Your immediate focus is to get the product up and running again.
For that, you’ll need to uncover why the issue is happening, test these hypotheses, involve anyone who can help with that, and deliver the fix. To streamline this process, maintain a centralized resource hub that can encompass the following:
- Tools for debugging (source code, email systems, logs, infrastructure, etc.).
- Examples of how to debug common issues that happened before
- Contacts of employees (subject experts) who can be involved in the process for faster resolution.
- Dashboards for real-time infrastructure monitoring and Golden Signals.
- Rules on how to behave in case of an incident
Ideally, compile these resources into a single, easily accessible runbook with links to all necessary documents tailored to your company's specific needs.
Learn
Incidents offer valuable learning opportunities, best explored through post-incident reviews or postmortems. Going through a postmortem as a team is a great chance to reflect on the shortcomings and plan for future improvements, such as uncovering vulnerabilities, preventing similar incidents, or decreasing the time to resolution.
This is where having a separate communication channel for incident tracking really pays out. After resolution, Incident Manager initiates a postmortem report that consolidates historical data, consultations with subject matter experts, and proposed improvements.
See Atlassian Postmortem Template for Confluence
To share or not to share
Similarly to communicating your product status, sharing postmortems with clients can be beneficial. It demonstrates transparency and commitment to improvement. Most companies share it as blogs for easy public consumption.

Post Mortem on Cloudflare Control Plane and Analytics Outage

Microsoft: Update on Azure Storage Service Interruption
Improve
Utilize postmortems
Postmortems are more than historical records; they're foundations for continuous improvement.
Follow these steps to turn postmortem findings into an action list:
- Prioritize findings based on their impact, urgency, and the potential for preventing similar incidents in the future.
- Put these items into the backlog of responsible teams to refine.
- Communicate expectations, deadlines, and the importance of completing the assigned tasks.
- Conduct regular status updates on these items.
- If the incident revealed deficiencies in existing processes or procedures, update them accordingly.
- Ensure that the incident response plan reflects the lessons learned and incorporates improvements.
Metrics
It’s a good idea to track your improvement progress by measuring at least two metrics: TTD and TTR.
- Time to Detect (TTD): how fast you notice an incident
- Time to Recovery (TTR): how quickly you fix it
Aim to keep both times short for better performance. These metrics can even guide team KRs and KPIs. The shorter the times, the better you are at incident handling.
Training
Well-trained employees are the most essential puzzle piece for a strong incident response. To avoid situations where your employees don’t know what to do, consider the following steps:
- Provide regular training sessions on response procedures and tools.
- Conduct drills to simulate real-life incidents.
- Create awareness campaigns about incident management.
- Include quiz-style training to reinforce learning.
- Familiarize employees with the incident response runbook.
Error budget

Align your improvement plan with your error budget. Integral to the domain of Site Reliability Engineering (SRE), the error budget is the acceptable amount of downtime or errors within a specified period that doesn’t compromise reliability.
It is essentially the inverse of the SLO. For example, if the SLO is 99.99%, the error budget is 0.01%. Then it means that it is acceptable for the service to be down for only 52 minutes and 35 seconds a year, which is the error budget for the year. In a different example, a 99.9% SLO permits up to 1,000 errors in a million requests over four weeks.
Utilize the error budget to balance reliability with innovation: underutilized error budgets allow for changes or new features, while exhausting it signals a need for stability. If that’s the case, focus on data gathering, monitoring dashboards, setting alerts, and understanding response strategies.
Difficulties
There are many things that can go wrong when creating a robust incident management framework. I’ll list key difficulties you’re likely to face.
- Insufficient staffing, tools, or budget
- Rigid workflows that are resistant to change
- Coordination complexity (especially for organizations with distributed teams)
- Because on-call availability requires working odd hours, it can be challenging to find the right balance between overtime compensation and scheduling that is both fair to employees and motivating
I know that the journey will not be easy, but overcoming difficulties is key to success.
Closing Thoughts
Do not postpone. Start implementing incident management with small steps. Always be ready. And remember: Anything that can go wrong will go wrong (Murphy's law).
Measure progress. Adopt the philosophy of Peter Drucker, a renowned business consultant and author of numerous business performance books: “If you can’t measure it, you can’t improve it.'
Learn from others. Learning from your mistakes makes you smart. Learning from other people makes you a genius.
This is an independent publication and it has not been authorized, sponsored, or otherwise approved by Medium, IBM, GitHub Inc, Cloudflare Inc, Microsoft.