Yurii Sokyran Software Engineer (Front-End)
How to Create a Web Extension for AI Image Generation

- #Web
• 20 min read
Midjourney, DALL-E and StableDiffusion image generators are very popular now. According to EveryPixel, more than 15 billion AI-created images have been generated in roughly 1.5 years. For reference, to create that many photos, humanity has spent 149 years.
No wonder tools that help generate better images come in handy for designers and generative art enthusiasts.
That’s why we had the following idea for a project during the Internal AI Hackathon: create a browser extension that will help users to create better prompts.

How does an Image Wizard work?
Right-click any image and select What’s the prompt? In a pop-up window, Image Wizard will give you a prompt you could use to generate a similar image with AI. For example:
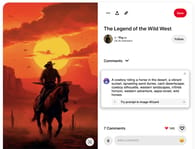
Now, we can copy and paste the prompt into Bing Image Creator powered by DALLE-3. The prompt would also work with Midjourney or Stable Diffusion. Here’s the result:
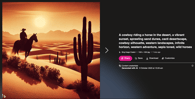
Looks cool right? Let’s break down how we created this extension, starting from the manifest.
As you can see, there’s also a button Try prompt in Image Wizard. When clicked, it opens a macOS app for generating prompts. But let’s focus solely on the extension in this article.
Anatomy of web extension
The manifest
Every extension requires a JSON-formatted file, named manifest.json, that provides important information. This file must be located in the extension's root directory.
We can start with the following manifest:
{
// Required
"manifest_version": 3,
"name": "Image Wizard",
"version": "1.0",
// Recommended
"description": "Get a prompt for selected image"
}
The code above won’t be enough for our extension, but we will complete it throughout the development process. Also we will look at the manifest in more detail after we look through the other crucial parts of the extension.
Content scripts
Content scripts are JavaScript files that run in the context of a webpage, allowing you to interact with and manipulate the DOM.
We used content scripts as our main entry point for creating popup and adding logic to it.
const main = () => {
const popup = document.createElement("div");
popup.classList.add("popup");
popup.classList.add("image-wizard");
const imgSrc = chrome.runtime.getURL("images/wizard.png");
const closeIcon = chrome.runtime.getURL("images/close-icon.svg");
const copyIcon = chrome.runtime.getURL("images/copy-icon.svg");
const openIcon = chrome.runtime.getURL("images/open-icon.svg");
popup.innerHTML = html`
<div class="top-bar">
<img id="close" width="20" height="20" class="close" src=${closeIcon} alt="Close" />
</div>
<div class="content">
<img width="32" height="32" class="logo" src=${imgSrc} alt="" />
<div>
<div class="text-container">
<div id="loadingText" class="text"></div>
<div id="resultText" class="text"></div>
</div>
<div class="button-container">
<button id="copy-text" class="copy-button">
<img src=${copyIcon} alt="Copy" />
</button>
<button id="open-imagewizard" class="open-button">
Try prompt in Image Wizard
<img src=${openIcon} class="open-icon" alt="" />
</button>
</div>
</div>
</div>
`;
document.body.appendChild(popup);
const close = document.querySelector("#close");
close.addEventListener("click", function () {
popup.style.display = "none";
});
const openWizard = document.querySelector("#open-imagewizard");
openWizard.addEventListener("click", function () {
const resultText = document.querySelector("#resultText");
window.open(`imagewizard://?prompt=${resultText.textContent}`);
});
};
main();
This code is mostly basic html-js manipulations except for this block:
const imgSrc = chrome.runtime.getURL("images/wizard.png");
const closeIcon = chrome.runtime.getURL("images/close-icon.svg");
const copyIcon = chrome.runtime.getURL("images/copy-icon.svg");
const openIcon = chrome.runtime.getURL("images/open-icon.svg");
Here we dynamically get the url of the image to use later inside our markup, like <img src=${openIcon} />.
To use it, we first need to declare accessible resources in our manifest:
"web_accessible_resources": [{
"resources": [
"images/*",
"fonts/*"
],
"matches": ["<all_urls>"]
}]
resources contains an array of relative paths to a given resource from the extension's root directory, and matches is an array of match patterns that specify which sites can access this set of resources. Here we use <all_urls> because we want users to be able to get prompts for images wherever they go.
If you build an extension for a specific marketplace or some website helper, you should set a more strict url pattern.
We have also declared fonts as accessible resources and can use them like that in our *.css files:
@font-face {
font-family: "FixelText";
font-style: normal;
font-display: swap;
font-weight: 200;
src: url(/fonts/FixelText-ExtraLight.woff2) format("woff2");
}
In order to add content scripts to your extension, you should declare it your manifest:
"content_scripts": [
{
"matches": ["<all_urls>"],
"js": ["content.js"],
"css": ["content.css"]
}
],
See content scripts in isolated worlds: Chrome Developer Docs
According to Chrome docs, extensions live in an isolated world, which is a private execution environment that isn't accessible to the page or other extensions. A practical consequence of this isolation is that JavaScript variables in an extension's content scripts are not visible to the host page or other extensions' content scripts.
You might think extensions are fully isolated, but there is a catch: your CSS can influence other websites.
If we have a CSS class with some pretty common naming:
.mainContainer {
background: indianred;
}
It will easily apply to the page you’re using.

List of APIs that content scripts can access
- 18n
- storage
- runtime:
- connect
- getManifest
- getURL
- id
- onConnect
- onMessage
- sendMessage
As you can see, there are generally three groups of APIs: translations (i18n), storage to work with local storage, and runtime to access resources or communicate with service-workers (more on that later).
All of that would be not enough to create a useful experience for a user, because we would need access to more sophisticated browser APIs. That’s why we have service workers.
Service workers (background scripts)
Service workers are a special kind of JavaScript that can run independently in the background, separate from web pages, and can manage tasks not directly associated with any user interface.
We add service workers to our extension by declaring it in manifest.json:
"background": {
"service_worker": "background-worker.js"
},
To allow usage of import, we set type of service worker to “module”:
"background": {
"service_worker": "background-worker.js",
"type": "module"
},
Service workers have access to a much broader list of APIs than the content scripts. That’s why they are useful for managing caching, offline mode, push notifications, background sync, and other tasks that do not require direct access to a web page's DOM (Document Object Model).
For example, we use contextMenus API to create new option in context menu like that:
chrome.runtime.onInstalled.addListener(() => {
chrome.contextMenus.create(
{
id: "click-img",
title: "What the prompt?",
contexts: ["image"],
},
() => void chrome.runtime.lastError
);
});
After that we add click listener for context menu items:
chrome.contextMenus.onClicked.addListener((info) => {
if (info.menuItemId === "click-img") {
// as we set `contexts: ["image"]` above, we can assume that `info.srcUrl` is an image url
console.log('clicked on image', info.srcUrl);
// other code ...
}
});
Long living communication
Service workers do not have direct access to the DOM so they can't interact with web pages directly. Instead, they communicate with other parts of the extension using the postMessage API.
Content scripts and service workers must communicate to maximize their individual strengths and mitigate limitations:
- Content scripts deal with the page and its elements, then send events to service workers.
- Service workers process the data, call the necessary browser APIs, and respond back with the result.
You can achieve this communication with one-off messages, but I don’t recommend this approach because the actual implementation seems hard and overwhelming.
One-off messages and its drawbacks
| In content script | In background script | |
|---|---|---|
| Send msg | browser.runtime.sendMessage() | browser.tabs.sendMessage() |
| Receive msg | browser.runtime.onMessage | browser.runtime.onMessage |
Here’s for example git snippet:
https://gist.github.com/DashBarkHuss/4da860d395cea57dd502e8978df1c488
As another user, I get Error: Could not establish connection. Receiving end does not exist.
Sometimes it's useful to have a conversation that lasts longer than a single request and response. In this case, you can open a long-lived channel from your content script to an extension page or vice versa using runtime.connect or tabs.connect, respectively. The channel can optionally have a name, allowing you to distinguish between different types of connections.
// draft-service-worker.js
let portFromCS;
function onConnected(port) {
portFromCS = port;
}
chrome.runtime.onConnect.addListener(onConnected);
portFromCS.postMessage({ type: "finish", value: data.value });
portFromCS.postMessage({ type: "openPopup" });
And from the content script we can connect and listen for that message:
// content-script.js
let myPort = chrome.runtime.connect({ name: "port-from-cs" });
myPort.onMessage.addListener((m) => {
if (m.type === "finish") {
// ...
} else if (m.type === "error") {
// ...
}
});
Below is the final implementation of our service worker code that implements long living communication with content script:
// service-worker.js
chrome.runtime.onInstalled.addListener(() => {
chrome.contextMenus.create(
{
id: "click-img",
title: "What the prompt?",
contexts: ["image"],
},
() => void chrome.runtime.lastError
);
});
let portFromCS;
function onConnected(port) {
portFromCS = port;
}
chrome.runtime.onConnect.addListener(onConnected);
chrome.contextMenus.onClicked.addListener((info) => {
if (info.menuItemId === "click-img") {
portFromCS.postMessage({ type: "openPopup" });
const timeoutId = setTimeout(() => {
portFromCS.postMessage({ type: "timeout" });
}, 29000);
return fetch("https://image-prompting-server/describe", {
method: "POST",
headers: {
"Content-Type": "application/json",
},
body: JSON.stringify({ url: info.srcUrl }),
})
.then((response) => {
response.json().then((data) => {
return portFromCS.postMessage({ type: "finish", value: data.value });
});
})
.catch((error) => {
return portFromCS.postMessage({ type: "error", value: error.message });
})
.finally(() => {
clearTimeout(timeoutId);
});
}
});
There is also a caveat with service workers – they can be terminated after inactivity.
Chrome stops a service worker if:
- inactive for 30 seconds (events or API calls reset the timer)
- a request, like an event or API call, exceeds 5 minutes
- a fetch() response takes over 30 seconds"
That’s why had to add timeout:
const timeoutId = setTimeout(() => {
portFromCS.postMessage({ type: "timeout" });
}, 29000);
We could postpone the timeout by calling the API, but for user experience it is better to reload the page and start again – the server might have a cold start and after a second request it will be faster.
Now back to manifest
The final version of our manifest.json is as follows:
{
"description": "Get a prompt for selected image",
"manifest_version": 3,
"name": "Image Wizard",
"version": "1.0",
"background": {
"service_worker": "background-worker.js"
},
"content_scripts": [
{
"matches": ["<all_urls>"],
"js": ["content.js"],
"css": ["content.css"]
}
],
"web_accessible_resources": [
{
"resources": ["images/*", "fonts/*"],
"matches": ["<all_urls>"]
}
],
"permissions": ["contextMenus"],
"icons": {
"128": "icons/icon-128.png"
}
}
We’ve added declarations for content scripts, service workers, and web-accessible resources in our configuration. Additionally, we've specified the icons and permissions properties.
- The
iconsproperty is very straightforward: it sets the icon of your extension. The icon is visible on the menu bar, extension list, etc. - The
permissionsproperty is more fun. Withpermissions, we can add more features to our extension, which is great. But you must understand why you need them, as you’ll have to explain each permission during the review process (provided you plan to add the extension to Chrome Web Store)
See the full list of permissions: Chrome Developer Docs
Browser compatibility: V2 vs V3
From Firefox to Chrome. In the beginning, I wrote this extension for Firefox because I use this browser the most in my everyday life. Also I have discovered that browser compatibility can be achieved with a manifest v2 and simple polyfill.
The plan was set – make an extension for one browser, use polyfill to make it work on another.
Manifest V3. My hopes were crushed when I discovered that Chrome Web Store now accepts only extensions with manifest V3. Moreover, polyfill won’t work because there are breaking changes in manifest V3. Chrome is much more popular than other browsers these days, so I had to stick with its requirements.
The problem is that Firefox and Chrome have a different way of building extensions. Chrome uses service workers for background work, Firefox uses background scripts. Essentially they do the same stuff – work with a broad list of browser APIs – but they are declared differently inside manifest and have different APIs usage. As of now, Firefox doesn't have service workers support in extension, and it seems like they don’t plan on deprecating background pages for now.
The main steps in migrating from V2 to V3:
- Update the manifest fields and API calls
- Migrate to a service worker— it replaces background page to ensure that background code stays off the main thread where it can hurt performance. This change also requires moving DOM, some extension API calls into offscreen documents.
- Replace blocking web request listeners — blocking or modifying network requests in Manifest V2 could significantly degrade performance and require excessive access to sensitive user data.
- Improve extension security – using remotely hosted code and execution of arbitrary strings are not allowed.
In our case, rewriting Firefox extension manifest V2 to Chrome extension manifest V3 was not that hard – we have a relatively small extension.
First of all, we had to just rename all of browser occurrences to chrome.
From this:
browser.contextMenus.create(
{
id: "click-img",
title: "What the prompt?",
contexts: ["image"],
},
() => void browser.runtime.lastError
);
To that:
chrome.contextMenus.create(
{
id: "click-img",
title: "What the prompt?",
contexts: ["image"],
},
() => void chrome.runtime.lastError
);
Next, we also had to update manifest.json, but we already showed you what’s inside.
Backend stuff
Okay, building the extension was fun – but how does it work internally? Where do you hide all of the magic you might ask?
Our backend can be split into three valuable components:
- Model that describes passed image.
- Carefully designed prompt that includes creative examples of other image prompts we strive for.
- OpenAI model that combines description and prompt to craft its own result.
How to make AI see stuff
Give AI its eyes: First, we need to describe an image we want. We used the Salesforce/blip-image-captioning-base model. It was enough to get started. We could’ve opted for a bigger model “Salesforce/blip-image-captioning-large”, but it required a more performant hardware.
Setup is pretty simple thanks to the Huggingface transformers library. First, we downloaded model files in order to get them locally. Here’s what inside save_model.py script:
import os
from transformers import BlipProcessor, BlipForConditionalGeneration
models_path = 'models/'
processor = BlipProcessor.from_pretrained("Salesforce/blip-image-captioning-base", local_files_only=False)
model = BlipForConditionalGeneration.from_pretrained("Salesforce/blip-image-captioning-base", local_files_only=False)
processor.save_pretrained(models_path + 'processor')
model.save_pretrained(models_path + 'model')
Now we could use these files and process an image:
processor = BlipProcessor.from_pretrained(models_path + 'processor', local_files_only=True)
model = BlipForConditionalGeneration.from_pretrained(models_path + 'model', local_files_only=True)
img_url = 'https://some-image.url'
raw_image = Image.open(requests.get(img_url, stream=True).raw).convert('RGB')
inputs = processor(raw_image, return_tensors="pt")
out = model.generate(**inputs)
image_desc = processor.decode(out[0], skip_special_tokens=True)
image_desc is a string like “a soccer game with a player jumping to catch the ball” or “a woman sitting on the beach with her dog”.
Adding necessary creativity to GPT
Normally, when we ask GPT-3.5 for a prompt based on an image description, we get different results. It can be both good and bad.
There is already pretty popular advice for creating good prompts, including a fantastic introductory article on prompts by Maksym Vatralik, a graphic designer and a colleague of mine.
So we gathered several examples of what are deemed high-quality and creative prompts for Midjourney.
With this approach, we formed our own prompt:
chatPrompt = """Act as a professional prompt engineer, who does the best prompts for Midjourney. Your prompts should short and concise. Different modifications for image should be separated with a comma. Your prompts should be in a style of the following prompts:
- a person in a boat in the middle of a forest, a detailed matte painting by Cyril Rolando, cgsociety, fantasy art, matte painting, mystical, nightscape
- a man riding on the back of a white horse through a forest, a detailed matte painting, cgsociety, space art, matte painting, redshift, concept art.
- The Moon Knight dissolving into swirling sand, volumetric dust, cinematic lighting, close up portrait
- a stunning image of a female face with light in it, in the style of unreal engine, richard phillips, animated gifs, macro lens, kelly sue deconnick, guillem h. pongiluppi, photo-realistic hyperbol
- Hyper detailed movie still that fuses the iconic tea party scene from Alice in Wonderland showing the hatter and an adult alice. Some playcards flying around in the air. Captured with a Hasselblad medium format camera.
- a Shakespeare stage play, yellow mist, atmospheric, set design by Michel Crête, Aerial acrobatics design by André Simard, hyperrealistic
- venice in a carnival picture, in the style of fantastical compositions, colorful, eye-catching compositions, symmetrical arrangements, navy and aquamarine, distinctive noses, gothic references, spiral group
Describe prompt for picture that will include: "{image_desc}".
Generated prompt:
"""
Finally, we pack chatPrompt inside Flask server script:
import os
from flask import Flask, request, jsonify
from flask_cors import CORS
import openai
import re
import requests
from PIL import Image
from transformers import BlipProcessor, BlipForConditionalGeneration
app = Flask(__name__)
CORS(app)
openai.api_key = os.environ.get('OPENAI_API_KEY')
models_path = 'models/'
processor = BlipProcessor.from_pretrained(models_path + 'processor', local_files_only=True)
model = BlipForConditionalGeneration.from_pretrained(models_path + 'model', local_files_only=True)
chatPrompt = """Act as a … Generated prompt: """
@app.route('/describe', methods=['POST'])
def query():
# parse the request body
data = request.get_json()
img_url = data['url']
raw_image = Image.open(requests.get(img_url, stream=True).raw).convert('RGB')
inputs = processor(raw_image, return_tensors="pt")
out = model.generate(**inputs)
image_desc = processor.decode(out[0], skip_special_tokens=True)
messages = [
{ "role": "user", "content": chatPrompt.format(image_desc=image_desc) },
]
response = openai.ChatCompletion.create(
model="gpt-3.5-turbo-instruct",
messages=messages,
max_tokens=512,
)
return jsonify({ "value": response['choices'][0]['message']['content'] })
if __name__ == '__main__':
port = int(os.environ.get('PORT', 8080))
app.run(debug=False, host='0.0.0.0', port=port)
Publish extension
Getting the right icon was easy – I just forwarded these requirements to our designers. Kudos to Maksym Vatralik and Anastasiia Satarenko for gold work!
Pss, a little secret: Our 'Image Wizard' icon was made by AI. So, even before you use it to generate AI prompts, there's already a bit of AI magic in the icon itself!

Next, we write the purpose of our extension. "Single purpose" can refer to one of two aspects of an extension:
- Single purpose limited to a narrow focus area or subject matter ("news headlines", "weather", "comparison shopping").
- Single purpose limited to a narrow browser function ("new tab page", "tab management", or "search provider")
In our case, we used this single purpose description: “Generate AI Art Prompts: Use Image Wizard to effortlessly create initial prompts for Midjourney and DALL-E AI art models based on any image you can find online. Right-click, select 'What's the prompt?', and get prompt.”

The hard part for me was the Permission justification. This is why I advocate for using only the essential permissions. Firstly, with fewer permissions, users have fewer concerns about the extension. Secondly, it streamlines your review process – you have less to explain and a reduced risk of being rejected by the Web Store team.
Conclusions
Image Wizard was developed as part of our internal hackathon. Concluding, this journey was not only a valuable learning experience for us but also led to a tool that our design service genuinely appreciated and utilized.
This article aims to serve as a helpful guide for developers, walking you through the entire process of creating browser extensions from scratch - from manifest and backend development to ensuring browser compatibility and ultimately, publishing.
Useful Resources
AI image generation
User interface
Cross-browser support
This is an independent publication and it has not been authorized, sponsored, or otherwise approved by FavoritePlates, @Ralgory_digital, Pinterest, GitHub Inc, Google LLC.