Nataliia Stulova Senior Research Scientist
AI in Software. Writing Assistants

- #Artificial Intelligence
• 56 min read
Introduction
DISCLAIMER This article has been partially written with an AI-based writing assistant. While the AI assistant provided much of the content, a human writer conducted thorough fact-checking to ensure accuracy and readability. Furthermore, the human writer wrote additional elements that could not be generated by the AI assistant, such as providing explanations in greater detail and adding further context to enhance understanding and semantic richness. The human writer also conducted additional research to verify facts and provide further sources for readers to consult. As such, while the AI assistant did provide input into this article, readers can rest assured that it was subjected to rigorous fact-checking by a professional human editor before being published.
The paragraph above is written entirely with the use of a GPT-3-based writing assistant and included here verbatim.
The first writing assistant programs started appearing on the market in the 1970s. Initially, developers attempted to create writing assistants using rule-based approaches, relying heavily on pattern-matching. While this proved effective, it had many limits, from being hard to scale to overall produced text quality being rather low. After the broader adoption of neural networks, natural language processing (NLP) tasks such as language translation, text summarization, and speech recognition began making notable progress. A great example is Google Translate, which in 2016 switched to a deep learning model from an older rule-based system.
Now AI-driven writing assistants provide background support, from basic spellcheck and autocorrection to full-blown intelligent composition interfaces that relatively easily generate entire paragraphs. Major news outlets like CNET already switch to co-writing with AI with humans doing the editing part.
Writing with the help of a digital assistant is now more accessible than ever, and examining the history of approaches to natural language generation can give us insight into its advances over the years. By comparing popular writing assistants today, we can better understand their capabilities and what benefits they can bring us when composing different texts. To add in some practicality to the mix, examples and demonstrations will be included, giving readers a hands-on approach with using such assistants to write better effectively.
Natural language generation
We have seen a shift in natural language generation technologies away from traditional, explicit modeling of language to that based on implicit patterns found within existing material. This transition occurred over two distinct phases; the collection of relevant data models and vocabularies needed for each phase was markedly different as well.
Top-down approach
1960s-1980s: To produce a piece of text in a given language we need to understand the grammar and have an annotated vocabulary of the language.
In the dawn of natural text generation, traditional approaches used rule-based systems with defined vocabularies and templates to manipulate symbols into written language. Early methods sourced concrete examples from abstract structures while gradually working down an abstraction ladder.
Grammars and vocabularies
Consider a simple grammar with 3 rules for English:
S -> NP VP ; Sentence is a NounPhrase (NP) and a VerbPhrase (VP)
NP -> N | Det N ; NounPhrase is a Noun (N) or a Determiner (Det) and a Noun
VP -> V NP ; VerbPhrase is a Verb (V) and a NounPhrase
Let's add a minimal vocabulary of 5 words too:
N -> 'John' | 'ball'
V -> 'hit' | 'kicked'
Det -> 'a' | 'the'
Now we can generate sentences like "John hit the ball" (1) or "a ball kicked John" (2):
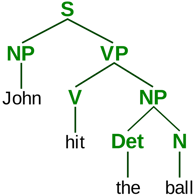
Grammars and vocabularies have limitations when it comes to natural language output. This approach only allows for generating sentences that are permitted by the grammar, using words included in the vocabulary – making meaningfulness difficult to assess without an external model of reality connected with this grammar. To represent semantic information better, adding an ontology or a probabilistic model is needed, which would enable more accurate sentence selection from those allowed (1) while ruling out unlikely ones (2).
Leveraging a grammar-and-vocabulary approach, automated strategies exist to generate complete phrases and larger texts. This technique of pattern matching and substitution is perfect for templatable tasks such as composing emails or weather forecasts with less manual work involved - however there are downsides; costs tend to be steep due the amount of expert input needed while scalability may not equate dependent on use case. However, all generated content remains syntactically correct whilst remaining semantically accurate too!
It is important to keep in mind that the natural language generation systems of this kind were not doing the reasoning themselves, but the said reasoning was already made explicit by humans. In the practical aspect, for texts generated this way we can explain why this or that sentence was generated, which can help to see precisely where the system struggles and focus the improvement effort.
Despite clear limitations, this approach was already enough to have meaningful conversations with chatbots, the prime example here being ELIZA.
ELIZA
ELIZA is a computer program that simulates a conversation with a human, using pattern matching and substitution methods. It was one of the first chatbots ever created and was developed by Joseph Weizenbaum at the Massachusetts Institute of Technology (MIT) in the 1960s. The program was designed to mimic a psychotherapist and used simple rules to respond to user input.
The program would take user input in the form of natural language and then rephrase it as a question. For example, if a user said "I am feeling sad," ELIZA would respond with "Why do you think you are feeling sad?" This gave the illusion of a more complex understanding of the user's words, but it was simply a pattern-matching program.

ELIZA was intended to be a proof-of-concept for the idea that computer programs could simulate human conversation. However, despite its simplicity, many people found the program to be convincing and even therapeutic. Some users would reveal personal information to ELIZA that they would not have discussed with a human therapist.

ELIZA is considered as a forerunner of modern conversational agents or chatbots, and a demonstration of how the expectations and perceptions of the user can influence the way in which a computer program is experienced. It also gave birth to the cognitive error, called The ELIZA effect — a phenomenon where people attribute human-like intelligence to a computer program or chatbot, even when its capabilities are quite limited.
The ELIZA effect can occur when people have unrealistic expectations of a computer program's abilities, or when they are willing to suspend their disbelief in order to have a conversation with the program. This can lead to people revealing personal information to a chatbot, or interpreting its responses in a way that makes them seem more human-like than they actually are.
This effect can be observed in many modern chatbots and virtual assistants, as people tend to project their own emotions and feelings into the interactions they have with them. Even though these systems are based on complex algorithms and pre-defined rules, people tend to attribute them with human-like intelligence and emotions.
Bottom-up approach
1990s-2000s: We will generate a text word-by-word, predicting most likely next word to complete the text peiece we already have.
In contrast to the grammar-and-vocabulary approaches, here we use many examples to generate a phrase. In contrast with explicit creation of a whole text/sentence structure, an alternative is to build a piece of text sequentially, focusing on one next word at a time. For such approach to work, we need a reliable method to predict the next word given its, typically previous, context - currently achieved with probabilistic and neural language models.
Language models
Language model itself is a probability distribution of a sequence of words, such that for every sequence the model can estimate a probability of it being a well-formed piece of text. For instance, such a model can predict that a sentence like "fox A jumps quick" will have a lower probability than a sentence "A quick fox jumps".
A simple example of a model for a text with only one sentence "The quick brown fox jumps over the lazy dog", its predictions could look like this:
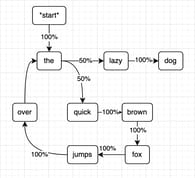
Models can be specialized for specific tasks, be it next word prediction (autocomplete and text generation), translation, sentiment analysis, or paraphrasing, but they can share a dataset of words, called corpus.
There are several important differences with the previous approach to natural language generation:
- a language model does not match grammar rules, it really focuses on producing a most probable output text for a specific task. As of now, most popular language models are implemented as neural networks.
- it's output accuracy depends on the quality of the corpus text it was trained on, the more words in it and the more variety in it, the better.
Models do not work directly with symbolic word dictionaries or raw texts of the corpus. Instead, the individual words are converted into an intermadiate, numerical representation called embedding.
Word embeddings
Word embeddings are a representation of individual words as real-valued numerical vectors.
Just a quick recap on vectors: they are mathematical abstract objects, that have a direction and size. Think of weather forecasts and how we describe wind: we usually use the direction (North, North-East, South-South-West etc.) and the wind strength in km/h. To encode the information about the direction and the size together, we typically assume that a vector has a starting point at 0, and only write down the coordinates of the end of the vector:
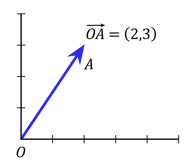
There are many possibilities on how to encode the words into vectors, but the shared underlying idea is make it in a way that captures semantic properties aof the words based on contexts where they occur. Simply put, if two words have similar meaning, after the encoding they should be similar in the same way too. In case of vectors, it means that similar words should be encoded into vectors of similar size and direction.
An embedding can look like this, each number in the encoding vector shows to which extent this word matches some semantic aspect:
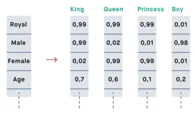
If before we would separage syntax features (like grammatical gender, case, number, tense) of the words from the semantic ones, and, for instance, talk about cats and volcanos together because both are plural nouns, in this representation we would focus more on the semantics and separate the two, because one of them explodes and the other does not.
We also do not define the semantic features explicitly, actually, as we are creating an embedding. Our task is to find such vector size and individual values, that similar words are described by vectors with similar values.
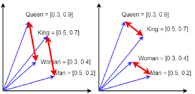
For instance, in this same example with the royalty, a 'King' and a 'Queen' are both about being a royal person, a 'Queen' and a 'Woman' are both about being female. If we only consider these two features, our ideal embedding would also capture that 'Man' and 'King' are related in a similar way, through the size and the angle of the vectors:
Quantity into Quality?
2010s-now: Everything, Everywhere, All At Once
So in bottom-up approaches the semantics of a word is taken into account in two different ways:
- when creating the embedding from the whole text corpus, allowing us to group similar words together
- when training a language model for a specific task to fix the use contexts of different words and relationships between them
However, the problem is the size of the context window needed for accurate modeling of a sequence of words in a piece of text. The longer the piece is, that harder it becomes to keep the context and relationship between words in memory, especially if you consider the words one-by-one. The latest technological breakthrough, that gave us the human-like text composition, like GPT-N family of models, solved the imprecise context problem with two innovative solutions.
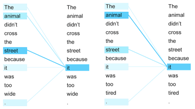
First, an attention mechanism was proposed. It allows to only relevant words be taken into the context instead of N preceding/surrounding/following words during the language model learning.
Second, the transformer architecture (the T in GPT) of the neural network was introduced, allowing for parallel, and not sequential input text processing. First, this allowed to take the text input at once in an impressive input window of 2048 tokens (token is a word or punctuation symbol, until this moment you have read about 2040 words in this article), and not word by word (and then use the attention mechanism to clarify the context and only select the words of interest). Second, it allowed to parallelize the computations, needed for the model training, resulting in faster training. Or, in being able to process much more data for a given amount of time. And remember, more data means more accuracy in predicting the words, as you see many more examples. A good illustation of the difference in the sequential and parallel information processing is music compposition. In the first case, it would be similar to hiring one musician and waiting for them to learn parts of several music instruments, and recording it one by one. In the second one, you hire and orchestra, where each musician learns just their instrument part, and then all play together at the same time.
Neural networks can be compared between themselves in many ways, but most often you would see a number of parameters. If we used a brain analogy, that would be roughly corresponding to the number of connections in the brain. The more connections, the more developed the brain is and the more things it can learn. And just how big are those transformer models getting? See for yourself:
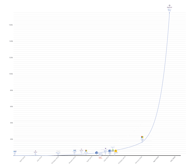
And this is basically the secret to the magic behind GPT-N models - especially after GPT-3 - their output seems to be so good because of how much text it had processed. An earlier incident of a Google engineer claiming that a similar transformer language model (LaMDA) is sentient was a great illustration of both the quality of the large language model-produced texts, and the ELIZA effect in action. Speaking of conversational systems, ChatGPT, the next model, also sometimes referred to as CPT-3.5 had even more data and learning on top.
ChatGPT
OpenAI released it at the end of November 2022, but as of now the access is limited: you can interact with it but not yet include it in your own software.
The core function of ChatGPT is to mimic a human conversationalist. It can improvise, answer test questions, write poetry, or compose music. ChatGPT doesn't search the internet to find an answer to a query. It relies on a model trained on books, articles, and websites to generate responses.
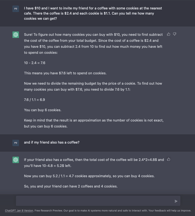
ChatGPT has limited knowledge of events that occurred after 2021. OpenAI admitted that ChatGPT "sometimes writes plausible-sounding but incorrect or nonsensical answers."
It's unreliable to use its answers directly without human review for the ethical aspect of the content. Depending on your prompt formulation, you can find jokes or stereotypes about certain groups or political figures. ChatGPT mainly learned from the internet, and it will carry on the same biases we have as a society - sexism, ageism, racism, and religion ones - in its writing.
Training them models
The increasing sophistication of transformer models for language generative tasks means that even professional editors often struggle to tell apart machine-created content from human-written work. This is a testament to the high quality of content generated by these models, indicative of how far computer-generated writing has come in recent years.
We, as humans, already have trouble distinguishing large language model-generated texts from human ones, even in quite niche areas of poetry and academic writing. But that's not all. On the path from ELIZA to ChatGPT we have come really far, with the latter one achieving some really astonishing results:
- ChatGPT is now an AWS Certified Cloud Practitioner with a score of 800/100 (720 required to pass the exam)
- also, it is a lawyer that scored 70% in a Practice Bar Exam
- a medical doctor to be, that answered corectly 70% of questions of the first step exam of the United States Medical Licensing Examination
- obviously, a writer that scored 91.6% on the New York State's Regents Examination in English Language Arts
- and, a pretty decent programmer that got 32/36 score in the 2022 AP Computer Science exams
So what are the text collections that large language models are training on?
Data
To train modern large language models we need quite a lot of data, that is:
- publicly available in digital format
- is human-produced
- passes minimal quality standards for formatting and coherence
- comes from different, diverse sources
Typically, the engineering teams behind the models use a mix of sources, for instance, this is what was used for GPT-3 training:

Some options are:
-
Comon Crawl is a dataset composed of years of crawling webpages, starting in 2008. While in itself it is an impressive source of information, it is also extremely polluted one. Some issues stemming from its creation method are presence of duplicated documents, dummy data (Lorem ipsum dolor sit amet...), and rubbish like web page navigation element names.
-
WebText is a collection of Reddit posts with at least 3 upvotes, cleaned up for duplicates.
-
Books two internet-based books corpora (Books1 and Books2). As of now we have no idea what exactly those books are about.
-
Wikipedia can be a nice multi-lingual high-quality dataset too, though for GPT-3 it was specifically the English version.
Two things are worth mentioning here:
- the models are usually trained predominantly in English texts, so despite automated translation working well some hicckups are expected during translation
- these corpora contain general texts, and is in some cases not sufficient to produce quality texts in specialised domains, such as medical one
However, people are already workign on localization, domain-adaptation, and other solutions.
Current issues
As with every technology, it solves some problems while creating new ones. Among the most pressing issues in the context of large language models there are concerns.
Energy use
energy to (re-)train: just the full training of the GPT-3 system is roughly equivalent to the total energy consumption of 150 houses in the USA for 1 year. A single server with 8 NVIDIA V100 GPUs will need 88 years to train it. If you rent the cloud computing power, the costs for the complete training can be close to $9M. There are many speculations about how much enegry it really took, so to verify the numbers above we reproduced the calculations from Lambda Labs and a Google engineer private blog post (though he did get some numbers wrong).
How we did the math here for the training time:
-
From the Table D.1 in the GPT-3 white paper (see page 46) we take the total amount of time that GPT-3 175B model needed for its full training: Total train compute (PF-days) 3.64E+03, or
if we do not use the E notation and use FLOPS for simplicity without the peta- SI prefix. -
We take the suggested standalone server setup from the LambdaLabs article, where they suggest using 8 x Tesla V-100 graphic cards. From the official NVIDIA Tesla V-100 GPU datasheet (or the relevant Wikipedia article) we get the processing power of this setup as
or to use same units as above. -
To find out for how long our 8-GPU setup will run to fully train the GPT-3 175B model we do this:
- as humas we usually represent such periods as
32500/365 = 88 years.
To do an estimate for the electrical power consumed for this training we do this:
-
from the same V-100 GPU datasheet we take the maximal power consumption as 250 W or 0.25 kW. Our full setup of 8 GPUs will then have consumption of
8*0.25 = 2 kW*h/hwhere h stands for hour. -
we get back to our total training time of 32500 days and the the total energy consumption as
- to once again translate this to something more relatable, we checked the data from the U.S. Energy Information Administration for average annual exectricity consiumption. The data from 2021 says that "the average annual electricity consumption for a U.S. residential utility customer was 10,632 kilowatthours (kWh)". From it, we get the
1560000 kW*h/(10632 kW*h/year) = 146 yearsof electricity supply for one house, or 146 houses for a year.
energy to use: even though this kind of models require much less energy for operation than for training, with millions of users the numbers scale up fast. As of now, daily carbon footprint from running ChatGPT can reach 23.04 kg CO2e. To put things in perspectivem that's like taking a train from Edinburgh to London (~650 km)!
Technology abuse
-
security risks: experts in the field report concerns over potential use of the technology for scams and phishing. It can also help people to write malicios code, among other things.
-
malicious content: despite the OpenAI attempts to prevent offensive and malicious content generation], it is still possible, although not in a straightforward way, to generate hate speech, sexually offensive content, instructions on conducting crime and preparing explosives. This is not a new problem, in 2016 Microsoft had observed how their chatbot Tay was turning into a nazi on Twitter. Disinformation campaigns are another already exising tech misuse example.
Societal issues
-
legal: large language models are trained on large collections of texts and code availble online, but online does not equate to public domain, nor is it free to use. Discussions about copyright and appropriate use of those materials for machine learning are still ongoing, getting outside of the theoretical speculations to very legal lawsuits over copyright infringement.
-
ethics: with great power (to produce texts) comes great responsibility (where to use them), but looks like not in this case yet. Homework cheating and academic dishonesty are the first examples of the misuse of this new technology, with current anti-plagiarism and AI-generated text detection systems not yet being able to cope. While there are some attempts to moderate the use of the generative technology, like StackOverflow forum banning the use of ChatGPT altogether, how it will exactly be reliably implemented is still not clear. Moreover, the model trainig process also has a necessary phase with human enrollment, to grade the quality of text snippets generated, and sadly worker exploitation is a thing there.
Writing
-
biased writing: toxic and hate speech are not the only issues in texts of generative models that learn on internet dialogs. Reports from Berkeley, the DeepMind project, and MIT highlight numerous aspects of why sexist, ageist, religious and other biases in the texts will be persistent and will need human correction.
-
factual incorrectness: is another thing to look out for in the model-generated texts, and human factchecking is still needed. The issue is well-known and openly discussed by OpenAI.
-
prompt sensitivity: Large language models can be very sensitive to the quality of the prompt that is used. A prompt that is too general or includes random words can lead to results that are far from the desired outcome.
Assistants in practice
AI writing assistants are writing tools that directly apply the possibilities of large language models for text generation to streamline many text-related tasks. For instance, they can:
- translate text from one language to another,
- summarize long documents into shorter versions that capture the core concepts,
- generate new content based on prompts or topics,
- check grammar for errors and suggest corrections,
- assist in researching and organizing information for projects,
- detect and correct writing tone,
- and refine writing to improve structure, style and clarity.
Basically, they allow us to write more and with fewer errors, especially if it is a well-defined text like am email, blog post, or an ad with a product description. Most assitants look exactly like you would expect them to - a blank page with some tools, yet instead of just text formatting toolset you would have content-oriented tools in many flavors:
- minimalist editors
- generation-focused editors
- a mix of both worlds
Among other features these tools offer are SEO optimizations for texts, various integrations into editors, browsers, CMS systems, and even some web analytics options.
GPT-3-based tools
Most of the writing assistants on the market have GPT-3 running under the hood, for better or for worse, some are switching from their own models to it after the huge success of ChatGPT. It's not only dedicated tools - documentation systems like Craft and Notion join the club and incorporate GPT-3 into their products.
The differences behind all these tools are mostly not in the quality of writing, as they all rely on the same language model, but in the UI and their optimizations for various tasks. After all, the second big goal is writing automation in specific scenarios. The common approach is to achieve it through offering templates and integrations into other tools as plug-ins.
Templates do not always work perfectly from the first try, and even if a tool comes with a claim that it "can produce a thousand-word document in fifteen minutes", there still will be some work to do for the human writer. One review on the Extremetech website includes a full walkthrough of a writing experience with one of the GPT-3-based assistants.
Alternatives
There are still a few tools developed by private smaller-scale companies that do not rely on OpenAI's models, like WordAI/ArticleForge by a small company GlimpseAI, or Wordtune by AI21labs.
Started before the success of GPT-3, they keep working on their own models and fine-tune them for fewer use cases and languages but try to focus instead on the contect quality, specifically factual correctness, by training their models on different and (hopefully) better quality datasets. ArticleForge, an "end-to-end writer" tool, released a detailed blog post on the downsides of GPT-3 use and their motivation to keep workong on their own solution.
Conclusion
Overall, AI writing assistants are not yet mature but it is time to start familiarizing ourselves and experimenting with the technology. The advantages of AI writing assistants include being able to speed up the writing process and even partially automating some tasks.
However, there are also some issues associated with the use of AI writing assistants, such as sensitive data use, necessary factchecking, and review for ethical soundness, which need to be dome by the human writers. Despite these concerns and limitations, AI writing assistants represent a shift from writing to mostly guiding text production and reviewing the results.
The technology is here to stay, and it is important that we practice using it and learn where it can strengthen existing write flows.
Links
- prompt collection Marketing Manager ChatGPT Swipe